
Introduction
Let’s be honest, searching through massive amounts of data used to be about as exciting as watching paint dry. You’d type in exact keywords, cross your fingers, and hope the search gods smiled upon you. But here’s the thing: vector search changed the game entirely, and Qdrant is making it ridiculously easy to implement.
So, What’s Vector Search Anyway?
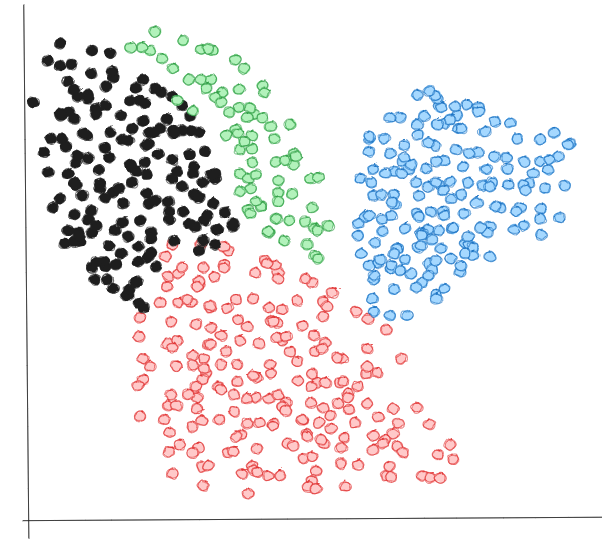
Picture this: you’re trying to explain to your friend what a “fluffy four-legged meowing creature” is. They immediately think “cat,” right? That’s basically what vector search does — it understands meaning, not just exact words.
Vector search takes your data (text, images, whatever you want) and turns it into numbers, specifically, lists of numbers called vectors. These vectors are like coordinates in space, except instead of just X, Y, and Z, we’re talking hundreds or thousands of dimensions.
The important part: similar things end up close together in this space.
Enter Qdrant: The Vector Database That Actually Makes Sense
Here’s where Qdrant comes in. Think of Qdrant as a really smart filing cabinet that not only stores your vectors but also has a photographic memory for finding similar ones lightning-fast. Built in Rust (which means it’s blazingly fast), Qdrant was designed from the ground up to handle vector search at scale without making you pull your hair out.
What makes Qdrant special? Well, for starters, it doesn’t try to be everything to everyone. It’s laser-focused on doing vector search really, really well.
How Does This Magic Actually Work?
- Data goes in: Feed data to an embedding model (OpenAI, Hugging Face, etc.).
- Vectors come out: Model generates arrays of numbers.
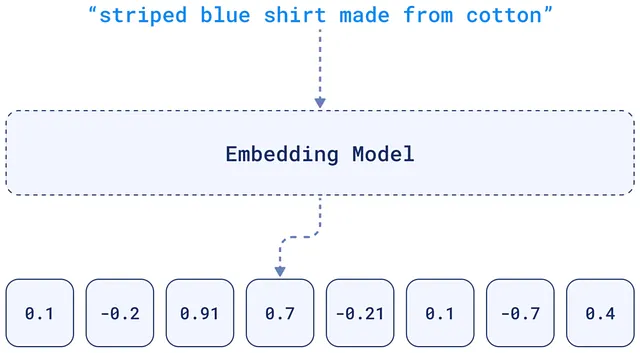
- Qdrant stores them: With metadata (IDs, descriptions, etc.).
- Search happens: Queries are vectorized and compared to stored vectors.
It’s like playing hot-and-cold, except Qdrant checks millions of hiding spots in milliseconds.
Let’s Build Something Real with Qdrant
Enough theory, let’s get our hands dirty. Here’s how you’d actually use Qdrant in Python (you can refer to the previous article for how to setup Qdrant in both Docker and python here):
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
import openai
import os
# First connect to Qdrant (you can run it locally with Docker)
client = QdrantClient(host="localhost")
# Create a collection: think of it as a table for your vectors
client.create_collection(
collection_name="my_recipes",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
# The dimension depending on the embedding model
# you have a lot of options for the distance parameter we will just use cosine
# ofc we need data
recipes = [
{"id": 1, "text": "Quick pasta with tomato sauce and basil"},
{"id": 2, "text": "Grilled cheese sandwich with extra cheddar"},
{"id": 3, "text": "Thai green curry with coconut milk"},
{"id": 4, "text": "Chocolate chip cookies from scratch"},
{"id": 5, "text": "Fresh garden salad with vinaigrette"}
]
# Generate embeddings and add to Qdrant
def embedding_fun(text):
response = openai.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return response.data[0].embedding
# Insert recipes
points = []
for recipe in recipes:
embeddings = embedding_fun(recipe["text"])
points.append(PointStruct(
id=recipe["id"],
vector=embeddings,
payload={"text": recipe["text"]}
))
client.upsert(collection_name="my_recipes", points=points)
# Now the fun part, searching
query = "I want something cheesy and warm"
query_vector = embedding_fun(query)
results = client.search(
collection_name="my_recipes",
query_vector=query_vector,
limit=3
)
for result in results:
print(f"Score: {result.score:.4f} - {result.payload['text']}")See? Not so scary. And the cool thing is, even though our query mentioned “cheesy and warm,” it’ll find the grilled cheese sandwich even if those exact words aren’t in the description.
Why Qdrant Instead of Other Vector Databases?
Look, there are plenty of vector databases out there. So why pick Qdrant? Let me tell you what sold me on it:
It’s Actually Fast
Written in Rust, Qdrant is optimized for speed. We’re talking about searching through millions of vectors in milliseconds. It uses a modified version of HNSW (Hierarchical Navigable Small World) algorithm that’s been tuned specifically for real-world use cases.
You can read more about HNSW in the link below.
Filtering That Doesn’t Suck
Here’s something that drives me crazy about some of the other vector databases, their filtering is an afterthought. Qdrant lets you filter by metadata DURING the search, not after. Want to find similar products but only in the “electronics” category and under $100? Qdrant’s got you:
results = client.search(
collection_name="products",
query_vector=query_vector,
query_filter={
"must": [
{"key": "category", "match": {"value": "electronics"}},
{"key": "price", "range": {"lt": 100}}
]
},
limit=5
)Collections and Sharding
Qdrant organizes data into collections (like tables in traditional databases), and when things get big, it automatically handles sharding. You don’t need a PhD in distributed systems to scale your vector search.
Avoid creating multiple collections unless necessary; instead, consider techniques like sharding for scaling across nodes or multitenancy for handling different use cases within the same infrastructure: An Introduction to Vector Databases.
Payload Storage
Unlike some vector-only libraries, Qdrant stores your actual data alongside the vectors. No need for a separate database to keep track of what vector belongs to what.

Real-World Stuff You Can Build
Alright, so what can you actually DO with this? Here are some ideas that aren’t just “build a chatbot” (though you can totally do that too):
Smart Product Recommendations
Instead of “customers who bought X also bought Y,” you can recommend products based on actual similarity. Customer looking at hiking boots? Show them similar outdoor gear, even if previous customers never bought them together.
Document Search That Gets Context
Searching through company documents, research papers, or legal contracts becomes actually useful when the search understands “quarterly revenue reports” should also find “Q3 financial statements.”
Multi-language Support Without the Hassle
Here’s a neat trick — many embedding models understand multiple languages. Search in English, find results in Spanish, French, whatever. No translation needed.
Image Search with Text
Using multimodal embeddings (like CLIP), you can search for images using text descriptions. “Red sports car on mountain road” actually finds relevant images, not just files named “red_car.jpg.”
The Technical Bits (For Those Who Care)
Let’s talk about what’s happening under the hood. Qdrant uses HNSW, which is basically a graph where each point connects to its neighbors at different levels. Think of it like a subway system with express and local trains — you take the express to get close to your destination quickly, then switch to local for the exact stop.
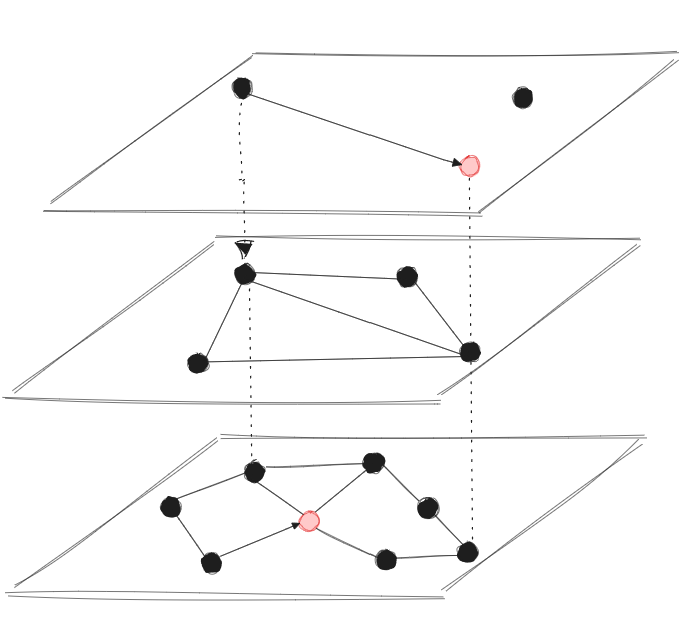 The beauty of HNSW in Qdrant is that it’s been optimized for real-world scenarios:
The beauty of HNSW in Qdrant is that it’s been optimized for real-world scenarios:
- It handles updates without rebuilding the entire index
- Memory usage is predictable and manageable
- Search speed stays consistent even as your data grows
Quantization: Making Things Smaller Without Losing Much
Qdrant supports scalar and product quantization, which is a fancy way of saying “compress vectors to use less memory.” It’s like JPEG for vectors — you lose a tiny bit of precision but save a ton of space. Perfect for when you have millions of vectors and don’t want to sell a kidney to pay for RAM.
Watch Neil Kanungo’s video about Qdrant binary Quantization here.
Deploying Qdrant: From Laptop to Production
One thing I love about Qdrant is how easy it is to go from development to production:
Local Development
Just run it in Docker:
docker run -p 6333:6333 qdrant/qdrantSmall Scale
Deploy on a single server with Docker Compose. Qdrant handles persistence, backups, the works.
Big Scale (you don’t need this for now)
Qdrant Cloud takes care of everything — clustering, replication, monitoring. Or self-host with Kubernetes if you’re into that sort of thing.
The Gotchas (Because Nothing’s Perfect)
Let’s be real, Qdrant isn’t magic. Here are some things to watch out for:
- Embedding Quality Matters: Garbage in, garbage out. If your embedding model sucks, Qdrant can’t save you.
- Dimension Size: More dimensions = more accuracy but also more memory and slower searches. Find your sweet spot.
- Index Building Time: For huge datasets, initial indexing can take a while. Plan accordingly.
- Distance Metrics: Cosine, Euclidean, Dot Product, etc.. pick the right one for your use case. When in doubt, cosine usually works well for normalized vectors (at least for me).
Tips from the Trenches
After building a few systems with Qdrant, here’s what I’ve learned:
Batch Your Operations
Don’t insert vectors one by one. Batch them up:
# Good
client.upsert(collection_name="something", points=list_of_many_points)
# Not so good
for point in list_of_many_points:
client.upsert(collection_name="something", points=[point])Use Metadata Wisely
Store useful metadata with your vectors. Future you will thank present you when you need to filter or debug:
payload = {
"text": original_text,
"created_at": timestamp,
"source": "user_upload",
"category": "technical",
"word_count": len(original_text.split())
}Monitor Your Metrics
Qdrant exposes metrics about search latency, index size, and more. Use them. Set up alerts. Don’t wait for users to complain about slow searches.
Where Qdrant Shines (And Where It Doesn’t)
Qdrant is awesome for:
- Semantic search at scale
- Recommendation systems
- RAG applications
- Similarity detection
- Multi-modal search
Maybe look elsewhere if:
- You just need simple keyword search
- Your data is highly structured and relational
- You have fewer than 10,000 items (might be overkill)
- You need complex SQL-like queries
The RAG Revolution (And Why Qdrant Fits Perfectly)
Can’t write about vector search in 2025 without mentioning the lovely RAG (Retrieval Augmented Generation). It’s basically giving LLMs access to your specific data instead of relying on what they learned during training.
Here’s the flow (for those who don’t know):
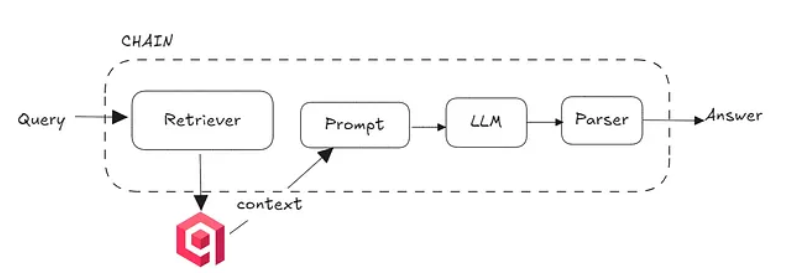 Image: Simplified RAG pipeline [Image by the Author]
Image: Simplified RAG pipeline [Image by the Author]
- User asks a question
- Convert question to vector
- Find relevant documents in Qdrant
- Feed those documents to an LLM
- Get an answer based on YOUR data, not Wikipedia
Qdrant makes this stupid simple with features like snapshot management for versioning your data and built-in distance scoring for relevance ranking.
Wrapping Up
Vector search isn’t just another tech buzzword, it’s genuinely changing how we build search and recommendation systems. And Qdrant? It’s making vector search accessible without requiring a team of ML engineers and a massive infrastructure budget.
The best part is you can start small. Spin up Qdrant locally, throw in some vectors, and see what happens. Once you see how much better semantic search is compared to keyword matching, you’ll wonder how you ever lived without it.
Want to dive deeper? Check out:
- Qdrant documentation
- Qdrant Discord community (seriously helpful folks)
- What is RAG by Qdrant
- Example projects on GitHub
- Efficient and robust approximate nearest neighbor search using HNSW graphs
- How I Built an Agentic RAG System with Qdrant to Chat with Any PDF
Now go build something cool. And when you do, drop me a line — I’d love to hear about it.
DM me on LinkedIn if you have any questions or need guidance, I would really love to chat!

(END)