over the past few years vector search has become foundational AI infra. its adoption has progressed through three phrases according to Qdrant, each driven by new application requirements and expanding capabilities. we’ve moved from cloud based retrieval to complex agentic memory and now we face the challenge of bringing this power into the physical world
think of this journey in three simple steps
- Wave 1: brought static search to cloud chatbots
- Wave 2: gave software agents a long-term memory to reason through tasks
- Wave 3: is where we are now: moving that “brain” out of the cloud and directly into physical devices like robots and phones

Wave 1: Static RAG
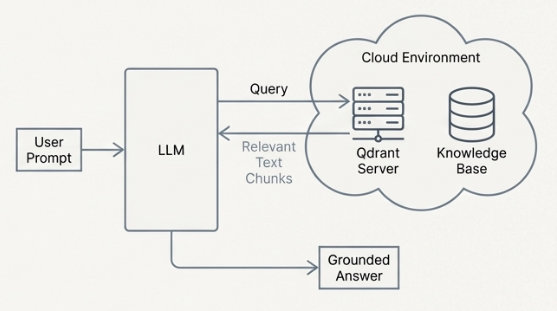
focused on cloud based context providers for llms performing text tasks like document search; read more here
Wave 2 : Agentic AI and long memory
vector search turned to become the long term memory module for autonomous software agents. the requirements expanded beyond simple retrieval to support ongoing reasoning, low latency updates and multimodal understanding
- architecture : still cloud based but with focus on real time ingestion and updates
- use case : storing experiences, enabling conversational memory, and powering complex multi step workflow
- technology: low latency updates token level reranking n and native multi-vector semantics
Wave 3: embedded ai in the physical world
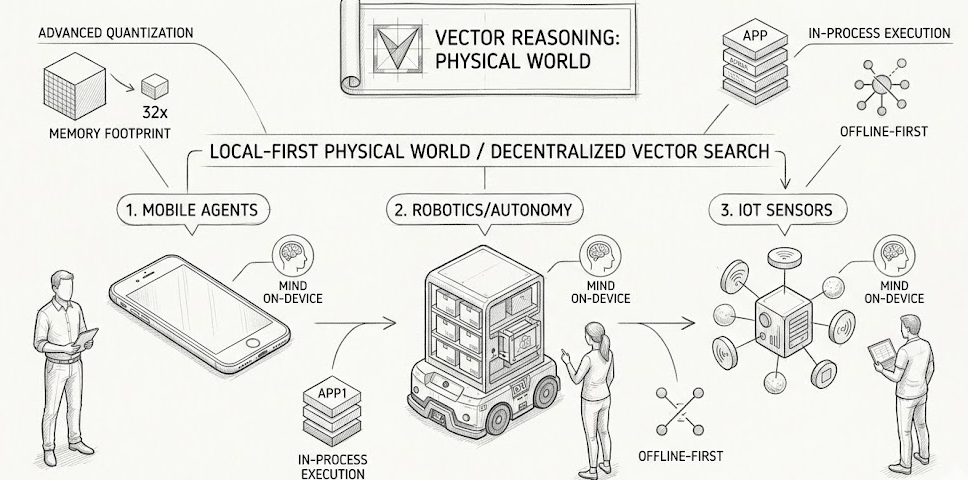
this brings vector based reasoning to the edge to env without reliable network access or cloud compute. AI is moving from servers into robots autonomous vehicles, mobile phones and IOT sensors. this shift brings an entirely new set of infra challenges
Qdrant edge[1] is specifically re-architected for this 3rd wave to ensure bandwidth independent operation, natively solving the issue where critical decisions cannot tolerate network round-trips for core retrieval operations
while these hardware barriers ; CPU, RAM and connectivity would stop traditional databases Qdrant edge was built to turn these limitations into its native strengths
some new set of imposed constraints : the traditional vector databases are not really designed for the edge. on device systems operate under strict non negotiable limitations that make cloud native approaches impractical or impossible

Edge AI maturity
we reached a moment in hardware where we have : powerful small-scale models like llama3.2 and gemma3&4 are now small enough to fit on mobile devices, yet smart enough to handle complex reasoning. this maturity makes on-device vector search not just possible but necessary
Qdrant edge : vector search re-architected for the 3rd wave
Qdrant edge[1] is a lightweight, in process vector search [1] engine designed for embedded devices, autonomous systems and mobile agents. it delivers Qdrant’s high performance search and filtering capabilities in a minimal library built for on device-AI
- Runs as an in process library, not a service
- optimized for low memory, low compute hardware
- local first, offline by default, with optional cloud sync
- supports on-device hybrid and multimodal search
Natively solving constraints of edge environments
Challenge
- strict resource constraints: most devices have no room for the background maintenance threads that standard databases use to stay fast
Solution :
- minimal footprint: because it is a lightweight library with no idle overhead
- advanced quantization[3] : it utilizes advanced asymmetric, binary, and scalar quantization to reduce memory footprint by up to 32x with over 97% accuracy [see Quantization Guide]
- in process execution: because no background daemons or update threads consuming resources
Challenge :
- latency & intermittent connectivity : decisions must happen in milliseconds on device without relying on persistent network
Solution
- offline-first execution : all retrieval and indexing runs fully offline without network access
- synchronous operations : the application has full control over execution , no unexpected background processes
- and again because it is in process library it eliminates network latency searches
Designed for scalable and multi tenant edge deployment
See [One collection to rule them All; Multi-tenancy blog ]
Challenge :
- Edge-to-Cloud Complexity : managing data sovereignty while maintaining a link to the cloud is a difficult balancing act
Solution
- “Optional Cloud Sync”: Run fully offline, and sync with Qdrant Cloud only when required for data transfer, model updates, or coordination
- “Hybrid Cloud Ready”: Integrates with Qdrant’s Hybrid Cloud architecture for unified management of on-prem, cloud, and edge deployments.
Challenge :
- Managing Thousands of Devices: scaling across a fleet of independent robots or phones requires isolated data and compute for every unit
Solution
- “Edge-Scale Multitenancy”: Supports payload- and shard-based tenant isolation, allowing each device (whether a robot or mobile unit) to function as an isolated tenant with its own dedicated compute and data boundaries
- “Native SDKs”: Provides native SDKs for target environments like Java (Android) and Swift (iOS/macOS), those enable developers to route queries across uneven edge workloads while keeping retrieval fully offline
Use cases :
- real Time Navigation in robotics and autonomy[4]
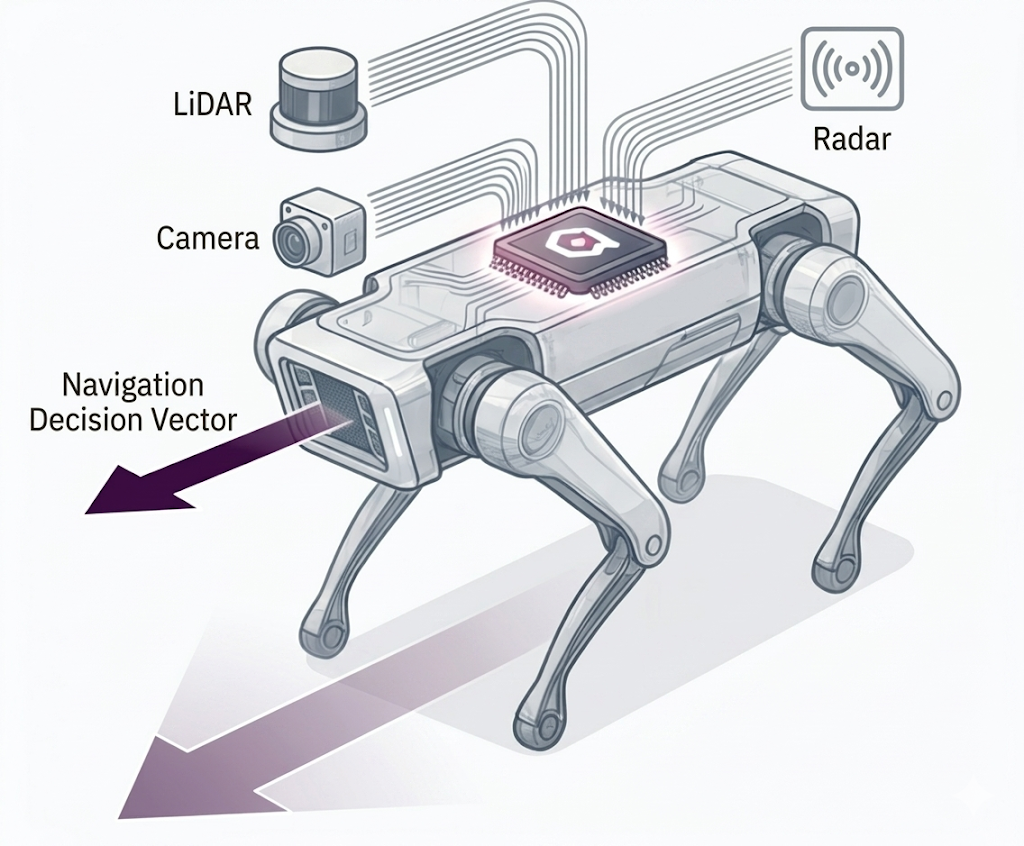
robots and drones must make real time decisions based on complex senor data in environments with no guaranteed connectivity
how Qdrant edge enables this ?
- on-device multimodal retrieval: runs multimodal search directly from onboard sensors (LiDAR, radar, camera embeddings) to identify objects, access terrain, and navigate complex spaces
- low latency perception: enables immediate decision making by eliminating the need for cloud round trips for perception tasks
- resilience: the system remains fully functional even when disconnected from central network
navigation is about knowing where to go; anomaly detection is about knowing when something is wrong. both require the same lightning fast local retrieval
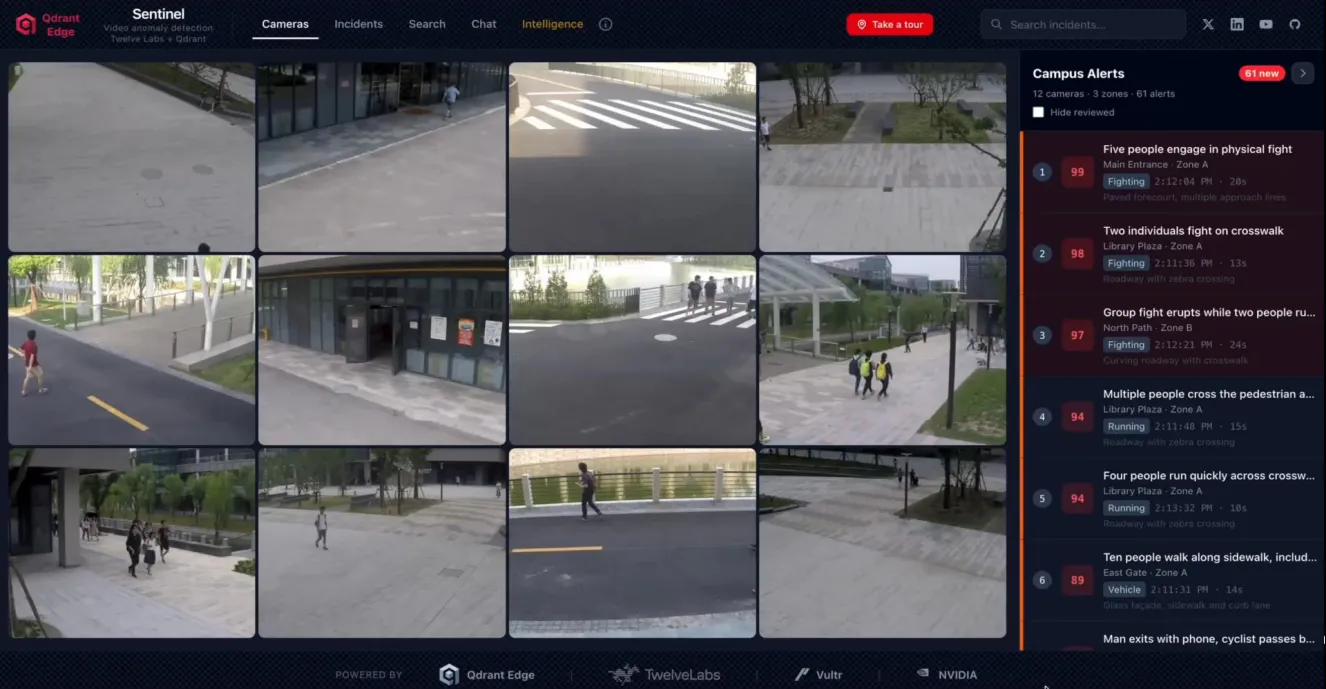
The Idea
Index video[2] embeddings of normal activity into Qdrant as a baseline. When a new clip arrives, embed it and search for its nearest neighbors. If the clip is far from anything in the baseline, it’s anomalous. No anomaly labels required, no retraining when new anomaly types emerge.
the system uses knn-based scoring formula where the anomaly score is calculated as 1 - mean cosine similarity [as shown in the Fig below].
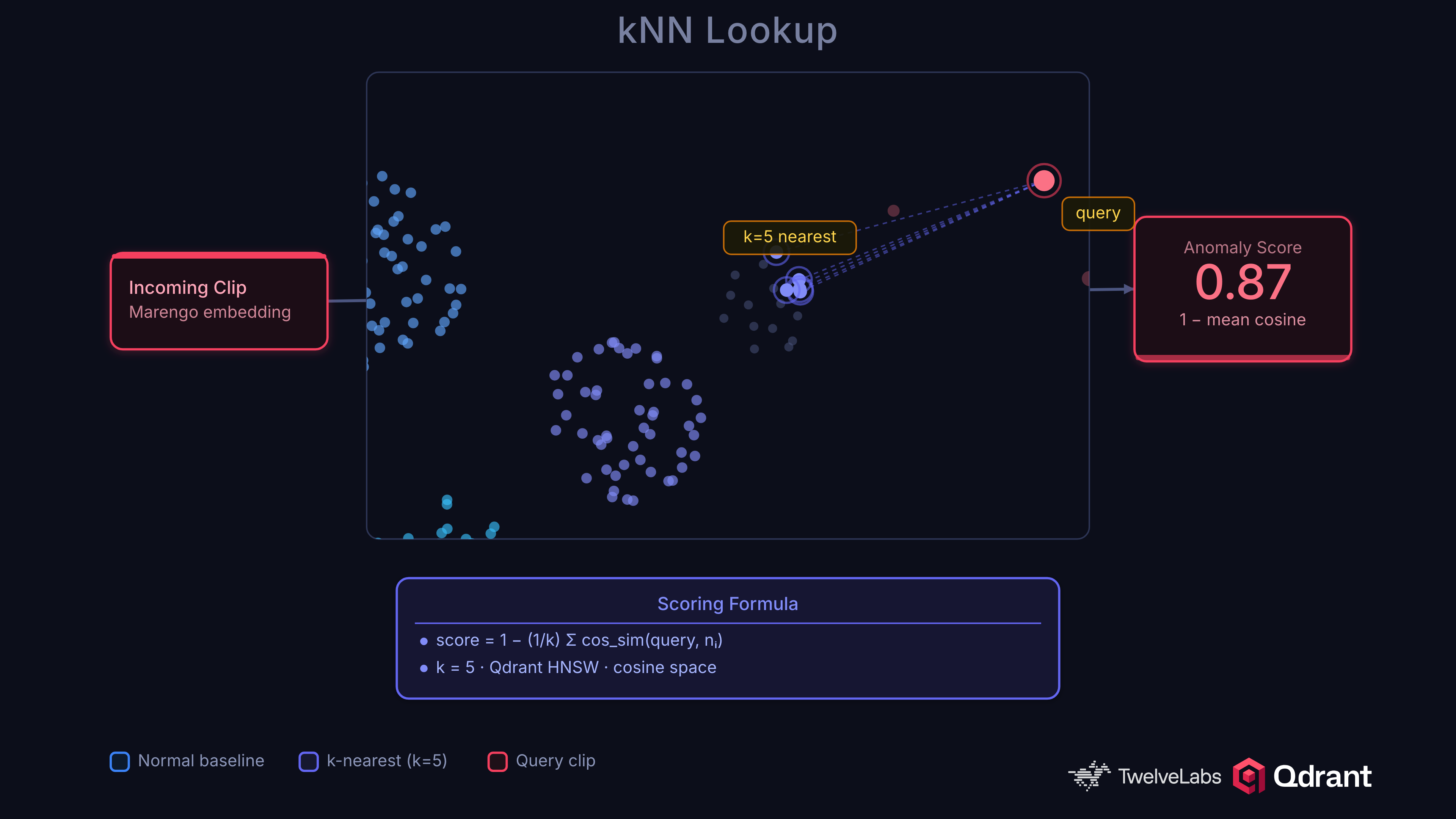
this works because the space of “normal” is learnable, but the space of “abnormal” is unbounded. A binary classifier trained on 13 crime categories will miss a forklift collision or a pipe burst. kNN distance from normal catches anything unusual by definition.
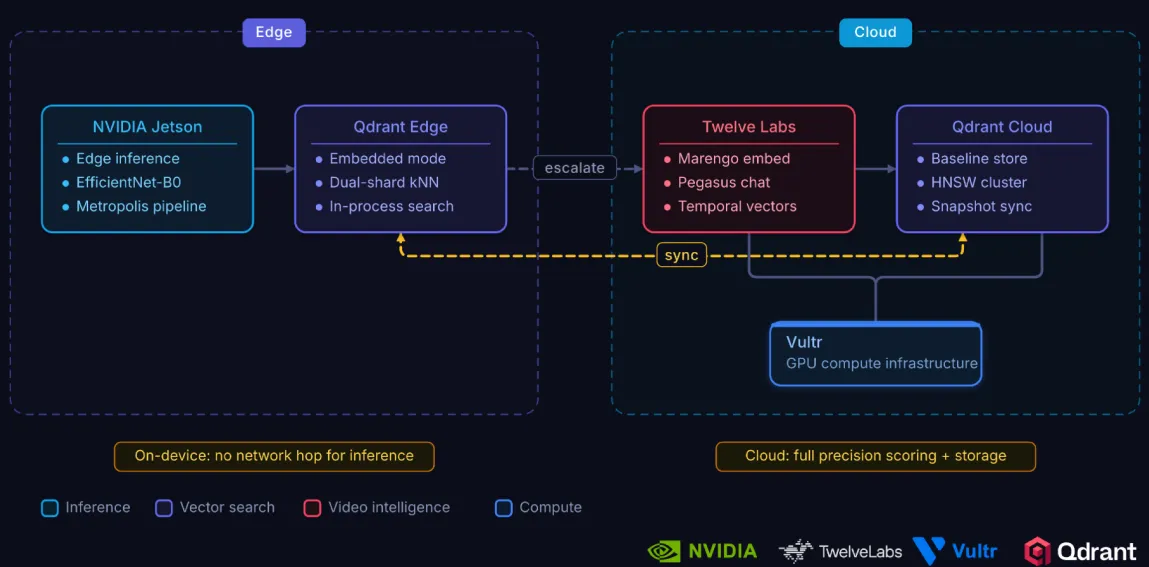
the evolution from cloud based RAG to embedded ai represents a paradigm shift. building the next generation of intelligent systems requires a new class of tooling that treats on-device reasoning as a 1st class capability
References :
- [1] Qdrant edge
- [2] Video anomaly detection from edge to cloud with Qdrant
- [3] Quantization Guide
- [4] Qdrant edge use cases

(END)